Q1: What are the key principles of system design?


System design is guided by several key principles that help ensure scalability, reliability, and maintainability. These principles include:
Q2: Explain the concept of load balancing and its importance in system design.
Load balancing is a technique used to distribute incoming network traffic across multiple servers. The main goal of load balancing is to ensure no single server becomes overwhelmed with too many requests, which can lead to poor performance or even failure.
Importance:
Q3: What is a microservices architecture, and what are its benefits?
Microservices architecture is a design approach where an application is composed of small, independent services that communicate over a network. Each microservice is responsible for a specific functionality and can be developed, deployed, and scaled independently.
Benefits:
However, microservices also introduce challenges, such as increased complexity in managing inter-service communication and data consistency.
Q4: Describe the CAP theorem and its implications in distributed systems.
The CAP theorem, also known as Brewer's theorem, states that in a distributed data store, it is impossible to simultaneously guarantee all three of the following properties:
Implications:
According to the CAP theorem, a distributed system can only provide two out of the three guarantees at any given time. Therefore, system designers must make trade-offs based on the specific requirements of the application.
For example, in a system where consistency and partition tolerance are prioritized, availability may be sacrificed during network partitions (CP system). On the other hand, in a system where availability and partition tolerance are prioritized, consistency might be sacrificed (AP system).
Understanding CAP theorem is crucial for making informed decisions about the architecture and behavior of distributed systems.
Q5: What is sharding, and how does it improve the performance of a database?
Sharding is a database architecture pattern where a large dataset is partitioned into smaller, more manageable pieces called "shards." Each shard is stored on a different database server to distribute the load.
How Sharding Improves Performance:
However, sharding introduces complexity in terms of data management, consistency, and query processing, which must be carefully managed.
Request question
Please fill in the form below to submit your question.
Q6: What are some common strategies for ensuring data consistency in a distributed system?
Ensuring data consistency in a distributed system is challenging due to the nature of distributed architecture, where data may be replicated across multiple nodes. Common strategies to maintain consistency include:
These strategies are often used in combination, depending on the specific requirements of the system, such as the need for strong consistency versus availability.
Q7: How does caching improve system performance, and what are some common caching strategies?
Caching is a technique used to store copies of frequently accessed data in a location that can be accessed more quickly than the original source. By reducing the need to repeatedly fetch the same data from the primary storage, caching can significantly improve system performance.
Benefits of Caching:
Common Caching Strategies:
Caching is a powerful tool, but it must be carefully managed to avoid issues like stale data or cache thrashing.
Q8: What is a message queue, and how does it support asynchronous communication in distributed systems?
A message queue is a communication mechanism used in distributed systems to enable asynchronous communication between different components. It allows messages (data) to be sent from one component to another, with the queue holding the messages until they are processed.
How Message Queues Support Asynchronous Communication:
Common Message Queue Implementations:
Message queues are essential for building resilient, scalable, and decoupled systems, especially in microservices architectures.
Q9: What is a Content Delivery Network (CDN), and how does it work?
A Content Delivery Network (CDN) is a distributed network of servers strategically placed across various geographic locations to deliver content to users more efficiently. The primary goal of a CDN is to reduce latency and improve the performance of content delivery, particularly for web applications, streaming media, and large files.
How a CDN Works:
Benefits of Using a CDN:
CDNs are widely used by websites, streaming services, and online platforms to ensure fast and reliable content delivery to users around the globe.
Q10: Explain the difference between vertical scaling and horizontal scaling.
Vertical scaling and horizontal scaling are two strategies used to increase the capacity of a system to handle more load.
Vertical Scaling (Scaling Up):
Horizontal Scaling (Scaling Out):
Conclusion:
Request question
Please fill in the form below to submit your question.
Q11: What are the key differences between relational databases and NoSQL databases?
Relational databases and NoSQL databases serve different purposes and have distinct characteristics that make them suitable for different types of applications.
Relational Databases:
NoSQL Databases:
Conclusion:
Q12: How would you design a rate-limiting system to prevent abuse of an API?
A rate-limiting system is designed to control the number of requests a user or client can make to an API within a specific time frame. This helps prevent abuse, such as DDoS attacks or excessive usage that could degrade the service for other users.
Key Components of a Rate-Limiting System:
Considerations:
Q13: Explain the concept of eventual consistency and its trade-offs in distributed systems.
Eventual consistency is a consistency model used in distributed systems where updates to a system may not be immediately visible to all nodes, but eventually, all nodes will converge to the same state given enough time.
How Eventual Consistency Works:
Trade-offs of Eventual Consistency:
Use Cases: Eventual consistency is often used in distributed databases like DynamoDB, Cassandra, and Riak, where high availability and partition tolerance are prioritized over immediate consistency.
Q14: What are the different types of databases used in system design, and when would you use each type?
In system design, different types of databases are used based on the application's requirements, such as data structure, scalability, performance, and consistency needs. The main types of databases include:
Q15: How do you design a highly available system, and what are the key components involved?
Designing a highly available system involves ensuring that the system is resilient to failures and can continue to operate with minimal downtime. The key components and strategies involved in achieving high availability include:
Request question
Please fill in the form below to submit your question.
Q16: What is the difference between synchronous and asynchronous communication in distributed systems, and when would you use each?
Synchronous and asynchronous communication are two fundamental paradigms for how components in a distributed system interact with each other.
Synchronous Communication:
Asynchronous Communication:
Conclusion:
Q17: Explain the concept of database partitioning and its types. How does partitioning improve system performance?
Database partitioning is the process of dividing a large database into smaller, more manageable pieces called partitions. Each partition is stored separately, which can improve performance, manageability, and scalability.
Types of Database Partitioning:
How Partitioning Improves Performance:
Q18: What is a circuit breaker pattern in system design, and how does it improve system resilience?
The circuit breaker pattern is a design pattern used in software architecture to improve the resilience and stability of a system. It prevents cascading failures and reduces the load on failing components by short-circuiting the flow of requests when a service or operation is consistently failing.
How the Circuit Breaker Pattern Works:
Benefits of the Circuit Breaker Pattern:
Use Cases: The circuit breaker pattern is commonly used in microservices architectures, distributed systems, and environments where services may be unreliable or subject to temporary outages.
Q19: How does a reverse proxy work, and what are its common use cases?
A reverse proxy is a server that sits between client devices and a backend server, forwarding client requests to the backend and returning the server's response to the client. Unlike a forward proxy, which routes outgoing traffic from clients, a reverse proxy manages incoming traffic from clients to servers.
How a Reverse Proxy Works:
Common Use Cases for Reverse Proxies:
Reverse proxies are widely used in web applications, content delivery networks (CDNs), and cloud computing environments to improve performance, security, and scalability.
Q20: What is the role of DNS in the internet infrastructure, and how does DNS load balancing work?
The Domain Name System (DNS) is a critical component of the internet infrastructure that translates human-readable domain names (e.g., www.example.com) into IP addresses that computers use to identify each other on the network. DNS is essentially the phonebook of the internet, allowing users to access websites and services using easy-to-remember domain names.
Role of DNS in Internet Infrastructure:
DNS Load Balancing:
DNS load balancing is a key technique used to improve the scalability, performance, and reliability of web applications, cloud services, and content delivery networks.
Request question
Please fill in the form below to submit your question.
Requirements:
Shorten a given URL.
Redirect to the original URL when the shortened URL is accessed.
Handle millions of requests.
Expire URLs after a specific time.
Components:
API Gateway
: To handle incoming requests.
Database
: To store the mapping between original URLs and shortened URLs.
Encoder/Decoder
: To generate and decode short URLs.
Flowchart:
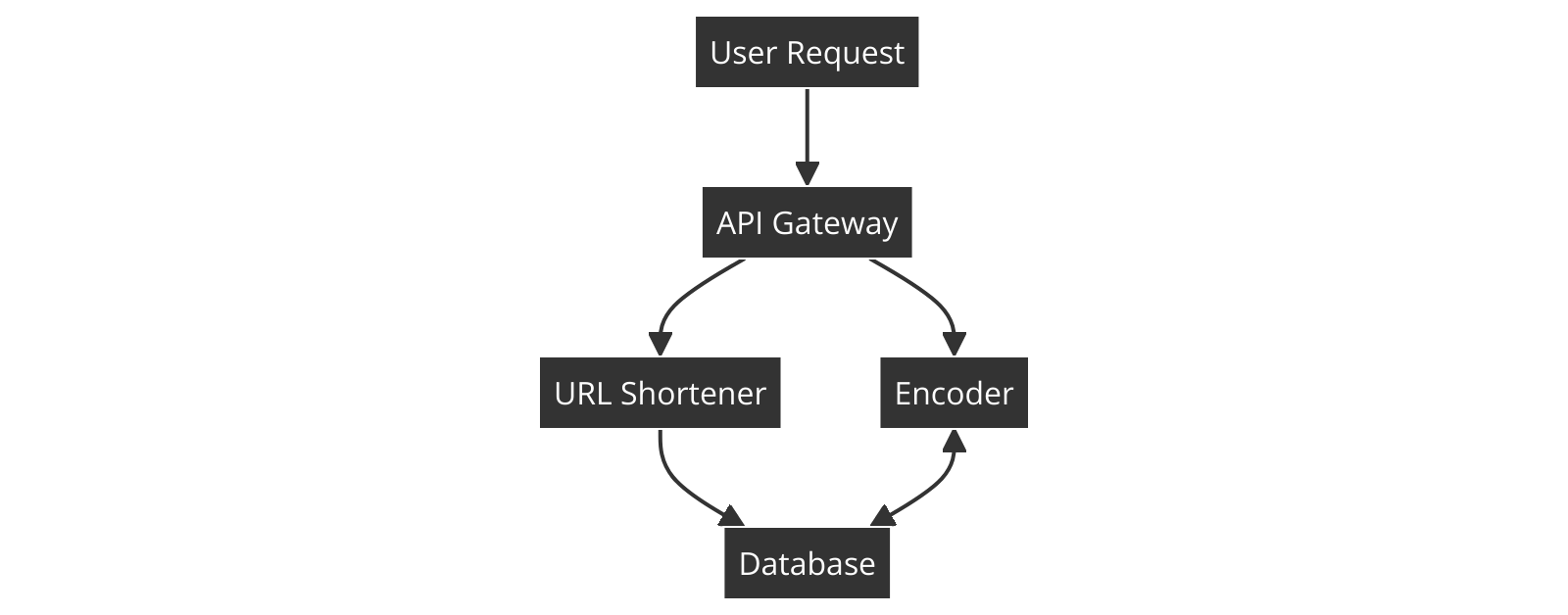
Approach:
Encoding:
Use a base62 encoding scheme to generate a short key for the long URL.
Database Storage:
Store the original URL against the generated short key in a database.
Redirection:
When a short URL is accessed, decode the key and look up the original URL in the database, then redirect.
Example Flow:
www.example.com/some-long-url
.
abc123
using base62 encoding.
abc123 -> www.example.com/some-long-url
in the database.
short.ly/abc123
, the service retrieves the original URL from the database and redirects the user.
Requirements:
Store frequently accessed data.
Distribute data across multiple nodes.
Handle cache invalidation.
Ensure fault tolerance and scalability.
Components:
Cache Nodes
: Multiple servers that store cached data.
Consistent Hashing
: To distribute data across cache nodes.
Cache Manager
: To handle cache eviction, invalidation, and updating.
Flowchart:
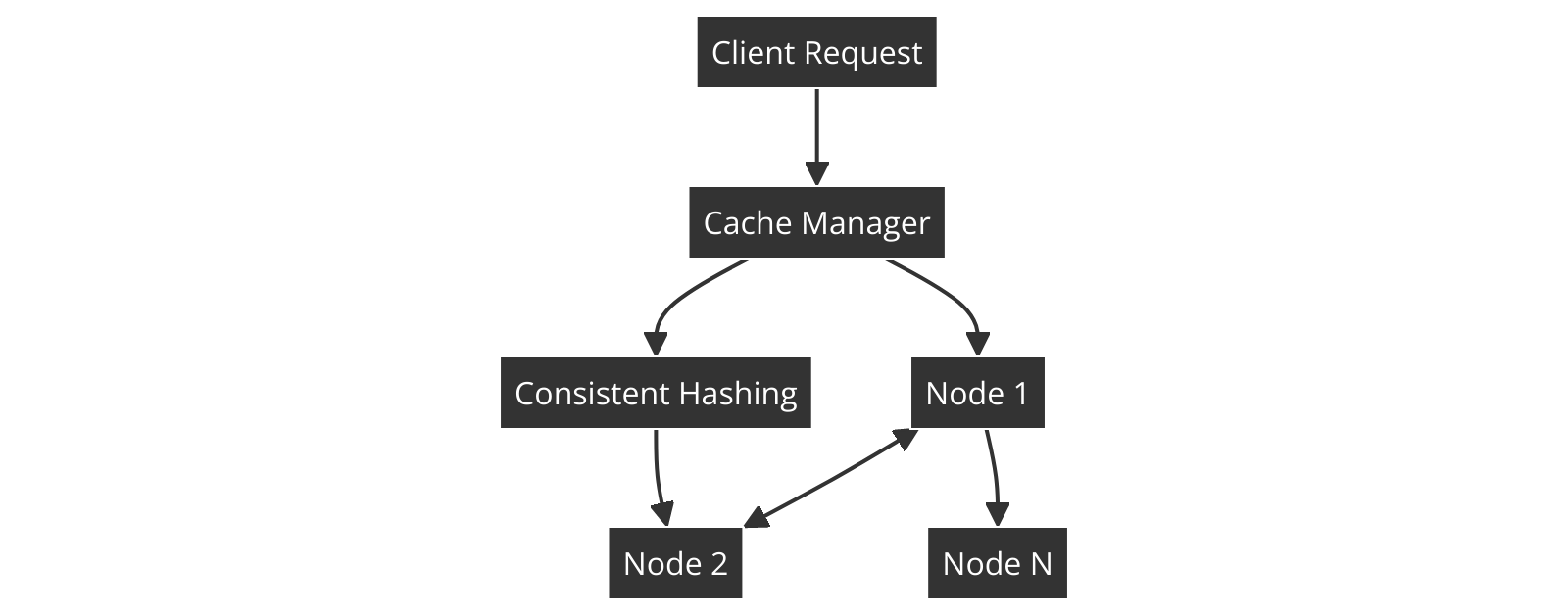
Consistent Hashing:
Implement consistent hashing to distribute keys across different cache nodes.
Cache Invalidation:
Use TTL (Time to Live) for cache invalidation.
Fault Tolerance:
Use replication or redundancy to ensure data availability in case of node failures.
Example Flow:
Requirements:
Send real-time notifications.
Handle different types of notifications (email, SMS, push).
Ensure delivery even during peak loads.
Components:
Message Queue
: To buffer notifications and handle peak loads.
Notification Service
: To process and send notifications.
Database
: To store user preferences and notification logs.
Flowchart:
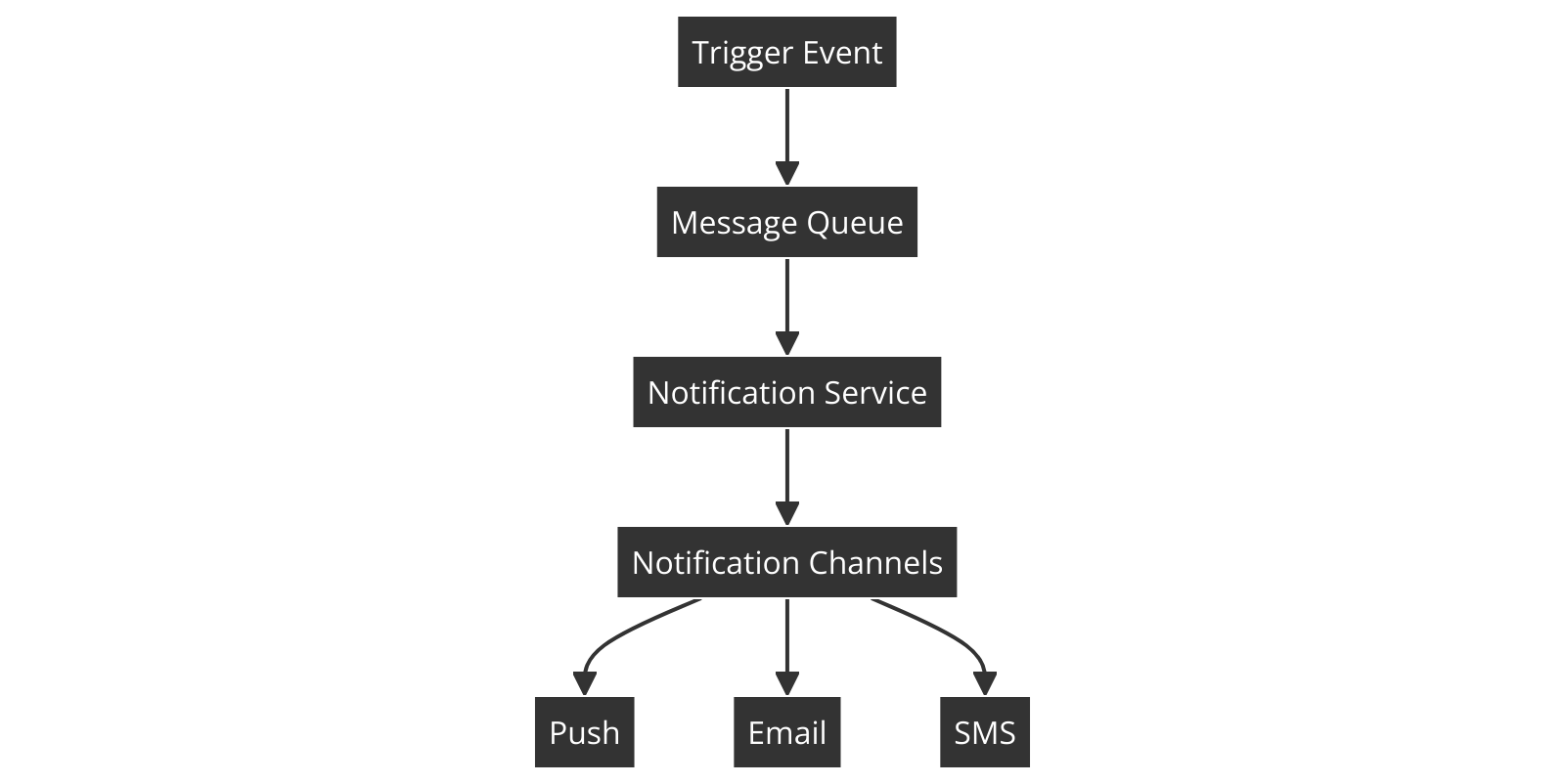
Approach:
Message Queue:
Use a message queue (like RabbitMQ or Kafka) to manage the flow of notifications.
Notification Service:
Process messages from the queue and send notifications through different channels (push, email, SMS).
User Preferences:
Check user preferences before sending notifications to avoid spamming users.
Example Flow:
Requirements:
Limit the number of API requests a user can make in a given time period.
Apply different limits for different users.
Prevent abuse while allowing legitimate use.
Components:
API Gateway
: To intercept incoming requests.
Rate Limiter
: To count and limit requests.
Database
: To store user request counts and limits.
Flowchart:
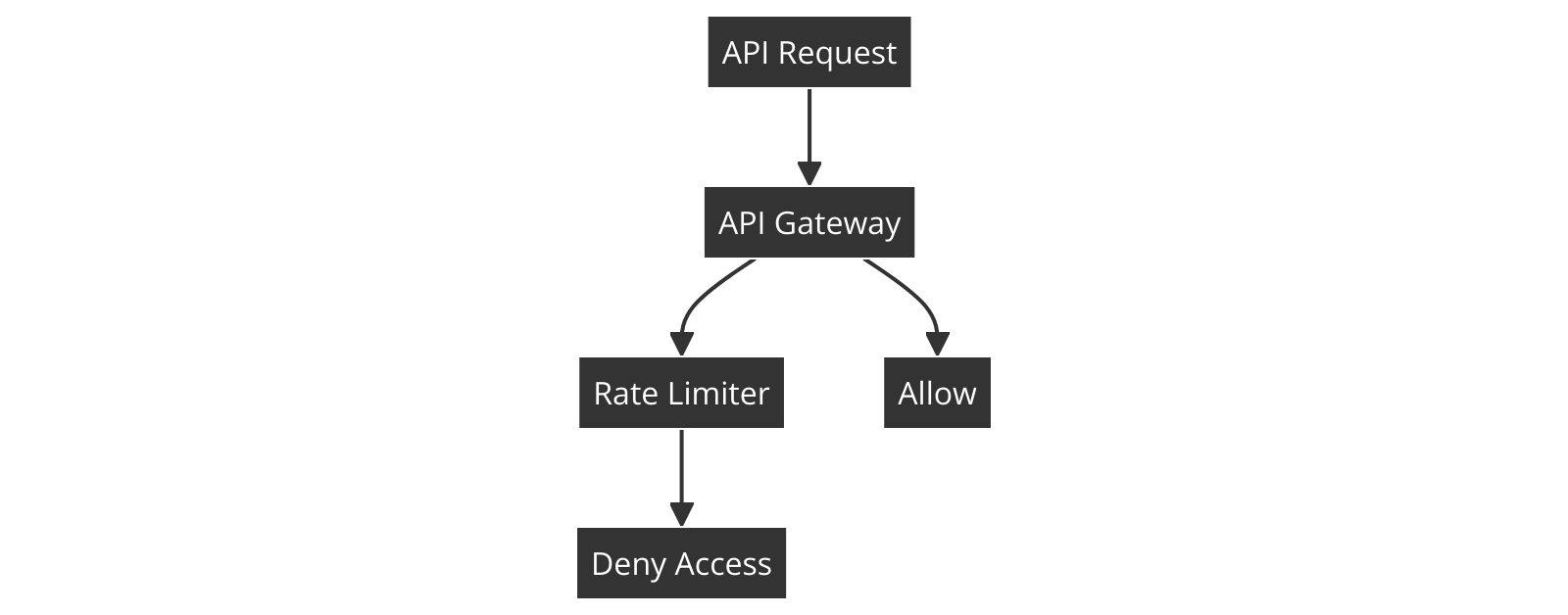
Token Bucket Algorithm:
Use the token bucket algorithm to limit requests.
Sliding Window:
Implement sliding window counters to track request rates over time.
Throttling:
Apply throttling to slow down or deny access when limits are reached.
Example Flow:
Requirements:
Real-time messaging between users.
Support for both one-on-one and group chats.
Message persistence and delivery guarantees.
User presence tracking (online/offline status).
Components:
WebSocket Server
: To handle real-time communication.
Message Service
: To handle message storage, retrieval, and delivery.
Database
: To store messages, user data, and group information.
Presence Service
: To track user online/offline status.
Flowchart:
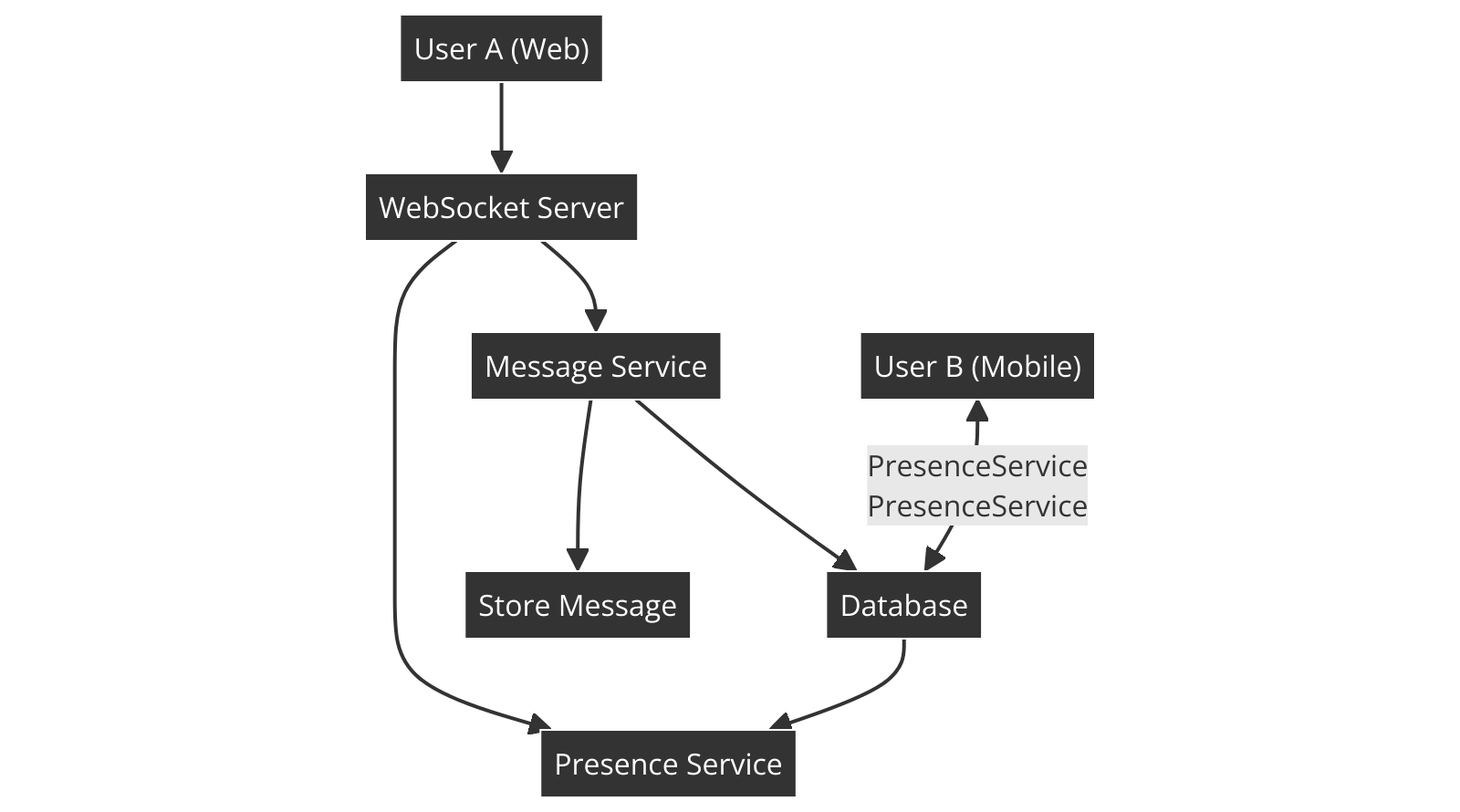
WebSocket Server:
Set up a WebSocket server to enable real-time, bidirectional communication between clients.
Message Service:
Handle messages sent by users, storing them in a database, and ensuring they are delivered to the intended recipient(s). For group chats, the message service will handle broadcasting messages to all members of the group.
Presence Service:
Track whether a user is online or offline, allowing others to see their status. This can be implemented using a simple heartbeat mechanism where the client periodically pings the server to indicate it's online.
Database:
Use a NoSQL database like MongoDB to store user data, chat history, and group information. This allows for fast retrieval of messages and scalability.
Example Flow:
Additional Considerations:
Scalability:
To handle a large number of users, the system can be scaled horizontally by deploying multiple WebSocket servers behind a load balancer.
Data Consistency:
For ensuring message delivery, implement acknowledgments from clients and retries on failure.
Security:
Encrypt messages during transmission using SSL/TLS and consider end-to-end encryption for privacy.
This design ensures a robust and scalable chat application that can handle real-time communication efficiently while providing a smooth user experience.
Request question
Please fill in the form below to submit your question.
Sign Up Now
Explore more on Workik





.png)


